ENAS is introduced by my mentor of my research on the classification of malignant thyroid nodules. This could be a good way to set the basic architecture of our net work. So I read this paper.
Efficient Neural Architecture Search via Parameter Sharing
https://arxiv.org/abs/1802.03268
Abstract
We propose Efficient Neural Architecture Search (ENAS), a fast and inexpensive approach for automatic model design.
Designing Recurrent Cells
Our search space includes an exponential number of configurations. Specifically, if the recurrent cell has N nodes and we allow 4 activation functions (namely tanh, ReLU, identity, and sigmoid), then the search space has 4 N × N! configurations.
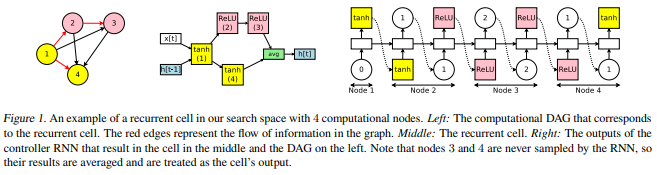
- At node 1: The controller first samples an activation function. In our example, the controller chooses the tanh activation function, which means that node 1 of the recurrent cell should compute h1 = tanh (xt · W(x) + ht−1 · W1(h) ).
- At node 2: The controller then samples a previous index and an activation function. In our example, it chooses the previous index 1 and the activation function ReLU. Thus, node 2 of the cell computes h2 = ReLU(h1 · W2,1(h) ).
- At node 3: The controller again samples a previous index and an activation function. In our example, it chooses the previous index 2 and the activation function ReLU. Therefore, h3 = ReLU(h2 · W3,2(h)).
- At node 4: The controller again samples a previous index and an activation function. In our example, it chooses the previous index 1 and the activation function tanh, leading to h4 = tanh (h1 · W4,1(h)).
- For the output, we simply average all the loose ends, i.e. the nodes that are not selected as inputs to any other nodes. In our example, since the indices 3 and 4 were never sampled to be the input for any node, the recurrent cell uses their average (h3 + h4)/2 as its output. In other words, ht = (h3 + h4)/2.
Controller
ENAS’s controller is an RNN that decides: 1) which edges are activated and 2) which computations are performed at each node in the DAG. Our controller network is an LSTM with 100 hidden units.
Training ENAS and Deriving Architecture
The training procedure of ENAS consists of two interleaving phases. The first phase trains ω, the shared parameters of the child models, on a whole pass through the training data set. The second phase trains θ, the parameters of the controller LSTM, for a fixed number of steps, typically set to 2000 in our experiments.
Designing Convolutional Networks
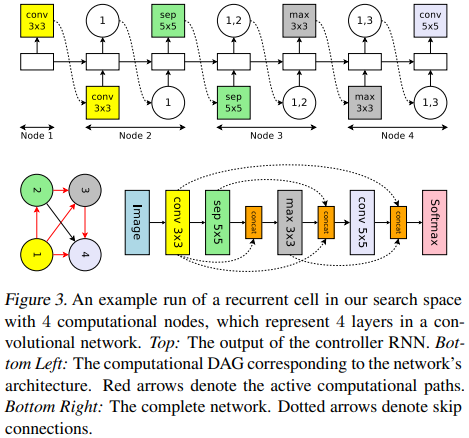
The controller RNN also samples two sets of decisions at each decision block: 1) what previous nodes to connect to and 2) what computation operation to use.
Designing Convolutional Cells
Rather than designing the entire convolutional network, one can design smaller modules and then connect them together to form a network.
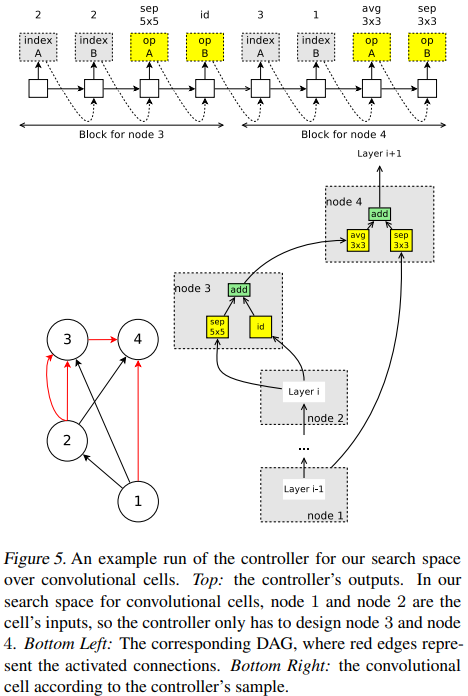
- Nodes 1, 2 are input nodes, so no decisions are needed for them. Let h1, h2 be the outputs of these nodes.
- At node 3: the controller samples two previous nodes and two operations. In Figure 5 Top Left, it samples node 2, node 2, separable conv 5x5, and identity. This means that h3 = sep conv 5x5(h2) + id(h2).
- At node 4: the controller samples node 3, node 1, avg pool 3x3, and sep conv 3x3. This means that h4 = avg pool 3x3(h3) + sep conv 3x3(h1).
- Since all nodes but h4 were used as inputs to at least another node, the only loose end, h4, is treated as the cell’s output. If there are multiple loose ends, they will be concatenated along the depth dimension to form the cell’s output.
P.S.
Actually, after reading this paper I only have the slightest understanding of this Net Work, and as for the details like what’s really going on when training, and how do those parameters in one unit change and cast influence on another unit, they still seem quite unclear to me.
https://github.com/shibuiwilliam/ENAS-Keras This is Keras implementation of ENAS. I ran the file ENAS_Keras_MNIST.ipynb on my workstation with 2 GPUs of 1080ti, and found that it requires days to finish running. Then, I ran it on my data set of thyroid nodules, it still finished only 1/3 of the work load in 24h. Apparently, it’s unrealistic to use this method to build my network for its training price is too high to afford. But still this method could come handy in the future.
Besides, while collecting information about this method, I find something called auto-Keras, which is based on ENAS. It can figure out a suitable network architecture for the data you input, and then you can do some improving work based on it. It’s an open source project. I think it’s an excellent way to start a new network. I will do some digging about it in the future days.