Medical images are tricky to handle, especially when it comes to dealing with single-channel CT images. Regular CNN architecture can hardly capture the useful features of those images, so I think it would be effective to utilize spatial transformer in our model. Here’s some note about this unit.
Abstract
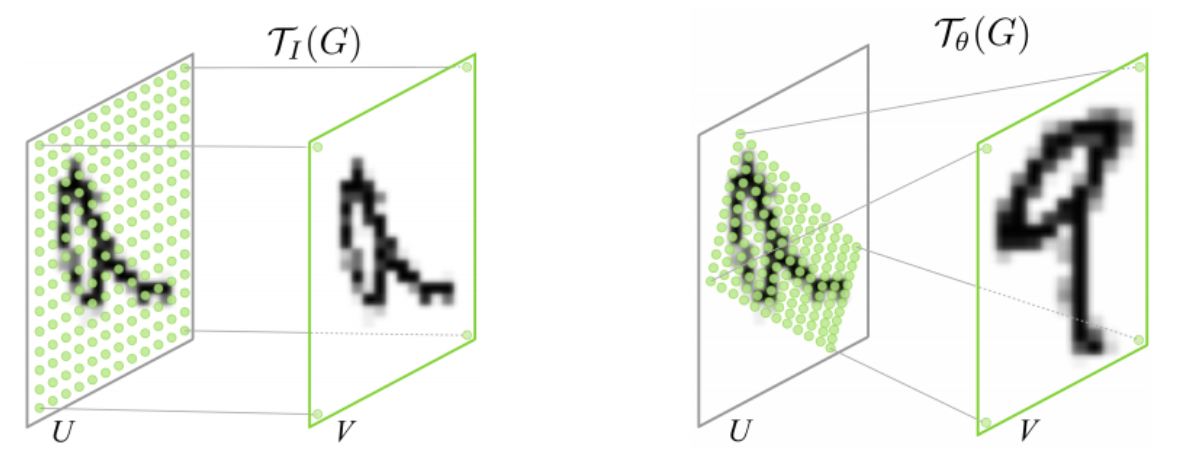
In this work we introduce a new learnable module, the Spatial Transformer, which explicitly allows the spatial manipulation of data within the network.

Basic Structure
The spatial transformer mechanism is split into three parts, shown in Fig. 2. In order of computation, fifirst a localization network takes the input feature map, and through a number of hidden layers outputs the parameters of the spatial transformation that should be applied to the feature map – this gives a transformation conditional on the input. Then, the predicted transformation parameters are used to create a sampling grid, which is a set of points where the input map should be sampled to produce the transformed output. This is done by the grid generator. Finally, the feature map and the sampling grid are taken as inputs to the sampler, producing the output map sampled from the input at the grid points.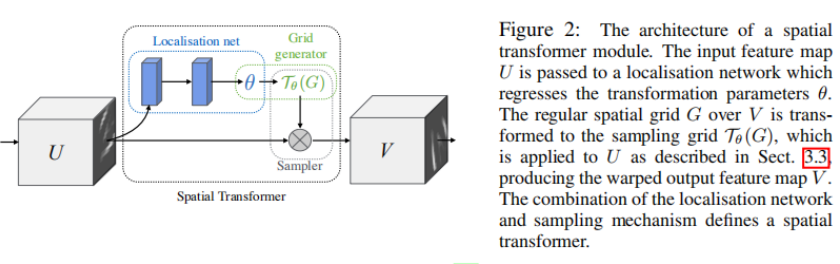
Localization Network
The localization network function floc () can take any form, such as a fully-connected network or a convolutional network, but should include a final regression layer to produce the transformation parameters θ. The size of θ can vary depending on the transformation type that is parameterized,
e.g. for an affine transformation θ is 6-dimensional as in (1). Affine transformation:
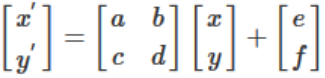
Parameterized Sampling Grid
We need to find the values of the points according to the coordinates of V, which are already set since the scale of it has been defined. In this affine case, the pointwise transformation is:
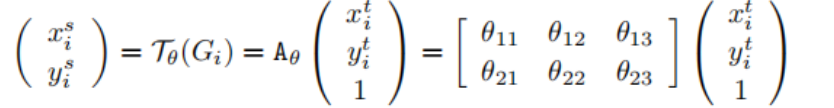
where (xit, yiy) are the target coordinates of the regular grid in the output feature map, (xis, yit) are the source coordinates in the input feature map that define the sample points, and Aθ is the affine transformation matrix.
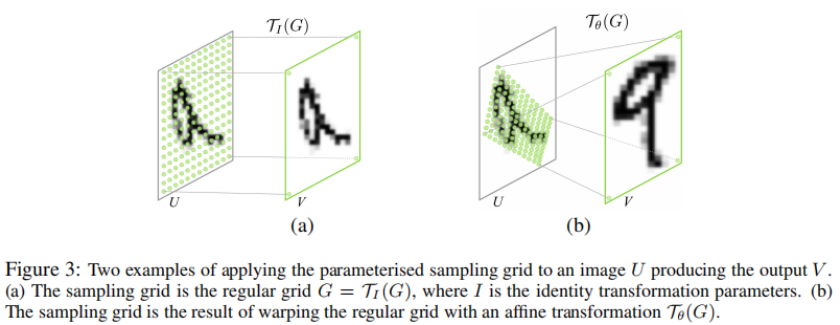
The transformation Tθ can also be more general, such as a plane projective transformation with 8 parameters, piece-wise affine, or a thin plate spline.
Differentiable Image Sampling
The coordinates we get from the grid above could be decimal, besides we can’t simply use the value from U for the values around this coordinate should also be taken into consideration, and the formula to do this is:
$$
V_i^c = \Sigma_n^H\Sigma_m^WU_{nm}^ck(x_i^s-m;\Phi_y)k(u_i^s-n;\Phi_y)\ \ \ \ ∀i\epsilon[1…H’W’] \ ∀c\epsilon[1…C]
$$
where δ() is the Kronecker delta function. A bilinear sampling kernel can be used, giving
$$
V_i^c = \Sigma_n^H\Sigma_m^WU_{nm}^c max(0,1-|x_i^s-m|)max(0,1-|y_i^s-n|)
$$
Spatial Transformer Network
The combination of the localization network, grid generator, and sampler form a spatial transformer. This is a self-contained module which can be dropped into a CNN architecture at any point, and in any number, giving rise to spatial transformer networks.